Bí quyết công nghệ của EzyPlatform - Phân trang dữ liệu
Back To Blogs
Post by:
 Young Monkeys - Founder
Young Monkeys - Founder
Young Monkeys - Founder
Date:
1731317233000
Một trong những tính năng mà bảng nào cũng phải dùng đó là phân trang dữ liệu, nếu không có một công nghệ được đóng gói một cách hoàn thiện sẽ dẫn đến những vấn đề nghiêm trọng.
Ba cách phân trang
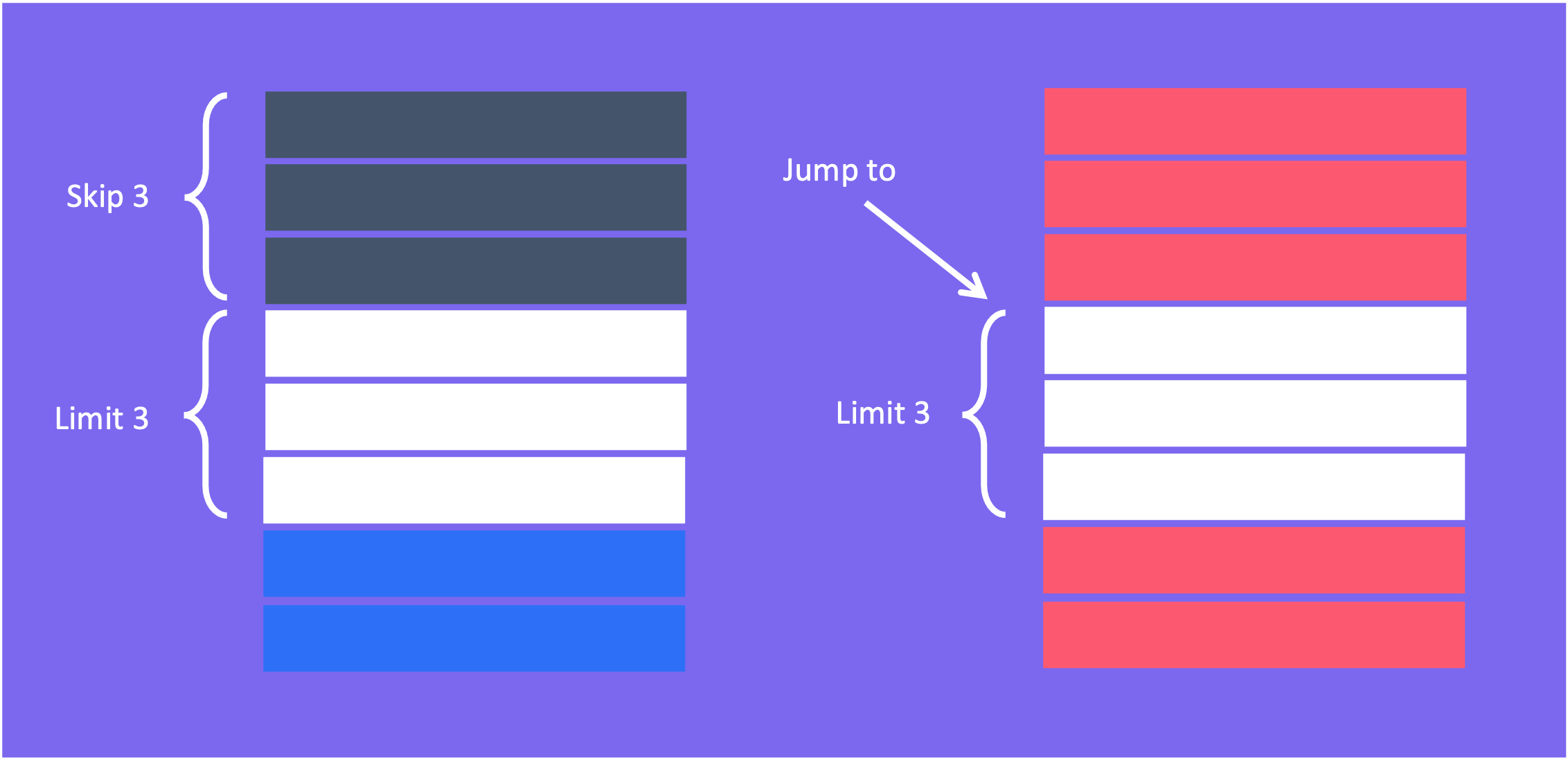
Có 3 cách phân trang dữ liệu mà chúng ta hay sử dụng bao gồm:
- Lấy toàn bộ dữ liệu của bảng ra để phân trang. Cách này đơn giản nhưng chỉ phù hợp với lượng dữ liệu nhỏ.
- Lấy dữ liệu theo offset và limit. Cách này cũng khá đơn giản tuy nhiên cũng chỉ phù hợp với lượng dữ liệu vừa phải khoảng vài chục nghìn đến 200,000 bản ghi, vì nếu trang ở cuối thì vẫn cần duyệt qua toàn bộ bản ghi dẫn đến chậm.
- Phân trang sử dụng con trỏ. Nghĩa là sử dụng các điều kiện so sánh lớn hơn hoặc bằng để tận dụng sức mạnh của BTree.
Bạn có thể đọc bài viết trên trang blog cá nhân của mình để nắm được nhiều chi tiết hơn nhé.
Cách đầu tiên lấy ra toàn bộ thì đơn giản rồi nên EzyPlatform tập trung vào việc nghiên cứu phát triển công nghệ để đáp ứng bài toán phân trang 2 và 3.
Cách làm thông thường
Hãy nói bạn có một bảng
ecommerce_product_books thế này:CREATE TABLE IF NOT EXISTS `ecommerce_product_books` ( `product_id` bigint unsigned NOT NULL, `author` varchar(120) COLLATE utf8mb4_unicode_520_ci NOT NULL, `author_user_id` bigint unsigned NOT NULL DEFAULT 0, `author_url` varchar(300) COLLATE utf8mb4_unicode_520_ci, `book_type` varchar(25) COLLATE utf8mb4_unicode_520_ci NOT NULL, `pages` int unsigned NOT NULL, `cover_type` varchar(25) COLLATE utf8mb4_unicode_520_ci NOT NULL, `affiliate` varchar(300) COLLATE utf8mb4_unicode_520_ci, `preview_link` varchar(300) COLLATE utf8mb4_unicode_520_ci, `distribution_company` varchar(250) COLLATE utf8mb4_unicode_520_ci, `publisher` varchar(120) COLLATE utf8mb4_unicode_520_ci, `released_at` datetime, PRIMARY KEY (`product_id`), INDEX `index_author_user_id` (`author_user_id`), INDEX `index_book_type` (`book_type`), INDEX `index_cover_type` (`cover_type`), INDEX `index_released_at` (`released_at`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
Được ánh xạ đến lớp
ProductBookpublic class ProductBook { @Id @Column(name = "product_id") private long productId; private String author; @Column(name = "author_user_id") private long authorUserId; @Column(name = "author_url") private String authorUrl; @Column(name = "book_type") private String bookType; private int pages; @Column(name = "cover_type") private String coverType; private String affiliate; @Column(name = "preview_link") private String previewLink; @Column(name = "distribution_company") private String distributionCompany; private String publisher; @Column(name = "released_at") private LocalDateTime releasedAt; }
Nhiệm vụ của bạn là phải truy vấn phân trang dữ liệu theo các điều kiện là:
- Tác giả.
- Loại sách.
Và phải sắp xếp theo các chiều:
public enum BookPaginationSortOrder { ID_DESC, // theo mã sách giảm dần. RELEASED_AT_DESC_ID_DESC // theo ngày xuất bản giảm dần, nếu ngày xuất bản trùng nhau thì sắp xếp theo mã giảm dần }
Khi tìm được kết quả bạn phải chuyển đổi từ dạng
ProductBook entity sang dạng model ProductBookModel thế này:@Getter @Builder public class ProductBookModel { private long productId; private String author; private long authorUserId; private String authorUrl; private String bookType; private int pages; private String coverType; private String affiliate; private String previewLink; private String distributionCompany; private String publisher; private long releasedAt; }
Nghe đến đây thôi là bạn đã thấy mọi việc cực kỳ phức tạp rồi đúng không? Theo một cách thông thường bạn sẽ tạo ra một lớp repository kiểu thế này:
public interface ProductBookRepository extends EzyDatabaseRepository<Long, ProductBook> { @EzyQuery( "SELECT e FROM ProductBook e WHERE " + "e.authorUserId = ?0 " + "AND (e.releasedAt > ?1 OR (e.releasedAt = ?1 AND e.id > ?2)) " + "ORDER BY e.releasedAt DESC, e.id DESC" ) List<ProductBook> findBooksByAuthorAndReleaseAtGtAndIdGtOrderByReleaseAtDescAndIdDesc( long authorUserId, LocalDateTime releaseAtExclusive, long idExclusive, Next next ); @EzyQuery( "SELECT e FROM ProductBook e WHERE " + "e.bookType = ?0 " + "AND (e.releasedAt > ?1 OR (e.releasedAt = ?1 AND e.id > ?2)) " + "ORDER BY e.releasedAt DESC, e.id DESC" ) List<ProductBook> findBooksByTypeAndReleaseAtGtAndIdGtOrderByReleaseAtDescAndIdDesc( String bookType, LocalDateTime releaseAtExclusive, long idExclusive, Next next ); }
Trên thực tế hai hàm này là không đủ, tương ứng với dữ liệu truyền vào cần phải có những hàm sau:
- Hàm lấy dữ liệu phân trang lọc theo điều kiện tác giả, sắp xếp theo chiều id giảm dần.
- Hàm lấy dữ liệu phân trang lọc theo điều kiện tác giả, sắp xếp theo chiều ngày xuất bản giảm dần, id giảm dần.
- Hàm lấy dữ liệu phân trang lọc theo điều kiện loại sách, sắp xếp theo chiều id giảm dần.
- Hàm lấy dữ liệu phân trang lọc theo điều kiện loại sách, sắp xếp theo chiều ngày xuất bản giảm dần, id giảm dần.
- Hàm lấy dữ liệu phân trang lọc theo điều kiện tác giả, loại sách, sắp xếp theo chiều id giảm dần.
- Hàm lấy dữ liệu phân trang lọc theo điều kiện tác giả, loại sách, sắp xếp theo chiều ngày xuất bản giảm dần, id giảm dần.
Như vậy càng kết hợp nhiều điều kiện thì theo cách tính tổ hợp sẽ làm số lượng hàm cần phải viết nhân lên một cách khủng khiếp. Đó là con chưa kể các bước chuyển đổi dữ liệu và còn hàng chục, hàng trăm bảng, nếu bảng nào chúng ta cũng phải làm kiểu này thì có lẽ đã không thể có EzyPlatform hoàn thiện như bây giờ được.
Thiết kế lớp phân trang của EzyPlatform
Để giải quyết triệt để bài toán phân trang, EzyPlatform đã được trang bị một thiết kế như sau chỉ riêng cho phần phân trang này:
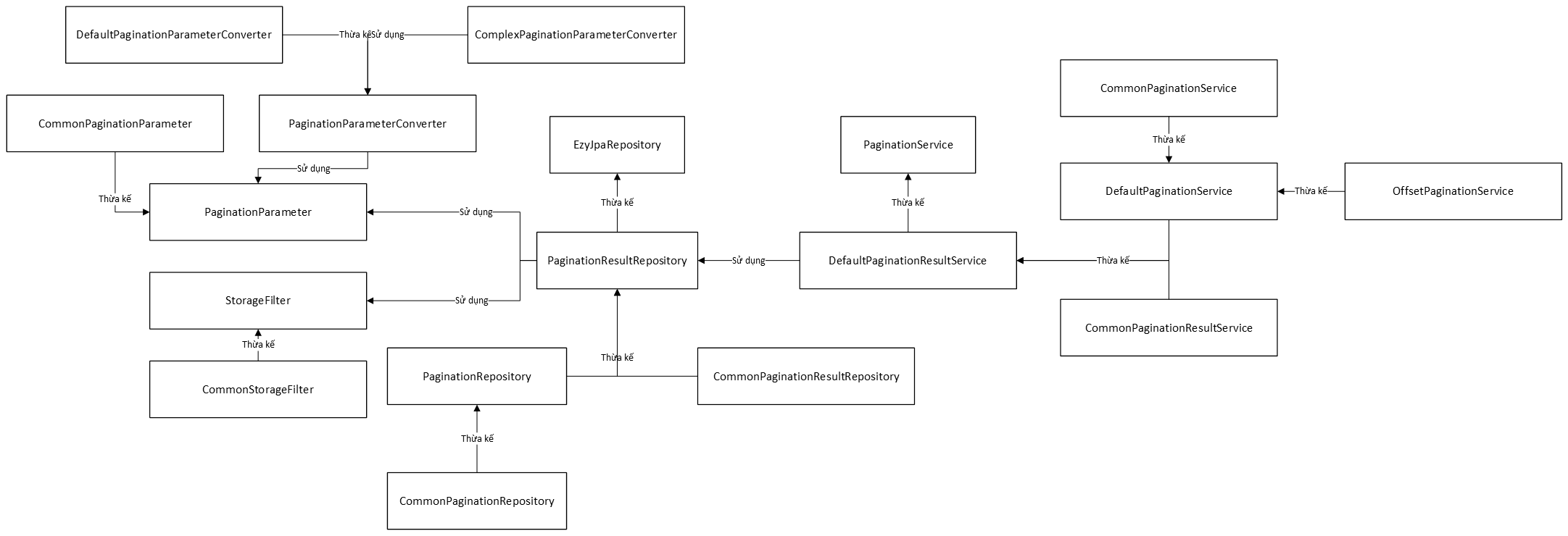
Ở đây chúng ta có các lớp:
- EzyJpaRepository: Đây là lớp cơ sở của thư viện EzyJPA, cung cấp các hàm để lấy dữ liệu từ cơ sở dữ liệu.
- PaginationResultRepository: Đây là lớp thừa kế
EzyJpaRepositoryvà bổ sung thêm các hàm truy vấn phân trang. - PaginationRepository: Đây là lớp thừa kế
PaginationResultRepositoryđể cài đặt sẵn một số hàm. - CommonPaginationRepository: Đây là lớp thừa kế
PaginationRepositoryđể cài đặt sẵn một số hàm. - CommonPaginationResultRepository: Đây là lớp thừa kế
PaginationResultRepositoryđể cài đặt sẵn một số hàm. - PaginationService: Đây là lớp chứa các hàm phân trang cơ sở và có càn đặt sẵn một số logic cho việc phân trang.
- DefaultPaginationResultService: Đây là lớp thừa kế
PaginationServiceđể cài đặt sẵn một số hàm. - CommonPaginationResultService: Đây là lớp thừa kế
DefaultPaginationResultServiceđể cài đặt sẵn một số hàm. - DefaultPaginationService: Đây là lớp thừa kế
DefaultPaginationResultServiceđể cài đặt sẵn một số hàm. - CommonPaginationService: Đây là lớp thừa kế
DefaultPaginationServiceđể cài đặt sẵn một số hàm. - OffsetPaginationService: Đây là lớp thừa kế
DefaultPaginationServiceđể cài đặt một số hàm cho kiểu phân trang offset, limit. - StorageFilter: Đây là giao diện cung các điều kiện lọc dữ liệu để đưa vào trong câu lệnh JPQL.
- CommonStorageFilter: Đây là giao diện thừa kế
StorageFilterđể cài đặt một số logic. - PaginationParameter: Đây là giao diện cung cấp các điều kiện phân trang để đưa vào câu lệnh JPQL.
- CommonPaginationParameter: Đây là giao diện thừa kế
PaginationParameterđể cài đặt môt số logic. - DefaultPaginationParameterConverter: Đây là lớp cài đặt các hàm cho giao diện
CommonPaginationParameter. - ComplexPaginationParameterConverter: Đây là lớp sửa dụng
PaginationParameterđể chuyển đổi qua lại giữa điều kiện phân trang và một chuối để gửi/nhận đến/từ client.
Để đưa ra được một thiết kế như thế này phải tốn đến hàng năm, từ khi có ý tưởng đến khi cài đặt, sửa đổi và hoàn thiện. Bạn có thể tham khảo mã nguồn được mở tại ezyplatform-sdk nhé.
Sử dụng phân trang
Kết quả của việc cài đặt phức tạp bên trong là sự đóng gói và dễ dàng sử dụng ra bên ngoài. Bạn có thể tham khảo hướng dẫn sử dụng phân trang trong tài liệu của Young Monkeys hoặc tham khảo mã nguồn của book-store.
Kế luận
Phân trang là một trong những tính năng cực kỳ mạnh của EzyPlatform cung cấp cho các nhà phát triển. Mặc dù cài đặt bên trong rất phức tạp nhưng việc sử dụng ở phía các nhà phát triển lại cực kỳ đơn giản, đây là một thành quả ngọt ngào.