EzyPlatform hỗ trợ đánh index dữ liệu thế nào?
Back To Blogs
Post by:
 Young Monkeys - Founder
Young Monkeys - Founder
Young Monkeys - Founder
Date:
1733675077000
Tìm kiểm theo kiểu dùng toán tử
LIKE %keyword% là đơn giản nhất trong tất cả các cách để tìm kiếm các bản ghi trong một bảng nào đó trong cơ sở dữ liệu. Tuy nhiên nó chỉ phù hợp khi số lượng bản ghi còn nhỏ, khi số lượng bản ghi tăng lên hàng trăm nghìn thì tốc độ truy vấn sẽ không còn đảm bảo nữa vì toán tử LIKE %keyword% có thể dẫn đến tìm kiếm toàn bộ các bản ghi trong một bảng, nghĩa là thực hiện một vòng for để tìm kiếm dữ liệu có chứa từ khoá, và đây là một trong những hành động thiêu đốt CPU.Thiết kế cơ sở dữ liệu
EzyPlatform cung cấp 2 bảng để đánh chỉ mục (index) là:
- ezy_user_keywords: Lưu dữ liệu người dùng được đánh chỉ mục.
- ezy_data_indices: Lưu dữ liệu được đánh chỉ mục nói chung.
Với mã nguồn như sau:
CREATE TABLE IF NOT EXISTS `ezy_user_keywords` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `user_id` bigint unsigned NOT NULL, `keyword` varchar(120) COLLATE utf8mb4_unicode_520_ci NOT NULL, `priority` int unsigned NOT NULL, `created_at` datetime NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `key_user_id_keyword` (`user_id`, `keyword`), INDEX `index_user_id` (`user_id`), INDEX `index_keyword` (`keyword`), INDEX `index_priority` (`priority`), INDEX `index_user_id_keyword_priority` (`user_id`, `keyword`, `priority`), INDEX `index_created_at` (`created_at`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci; CREATE TABLE IF NOT EXISTS `ezy_data_indices` ( `id` bigint unsigned NOT NULL AUTO_INCREMENT, `data_type` varchar(120) COLLATE utf8mb4_unicode_520_ci NOT NULL, `data_id` bigint unsigned NOT NULL, `keyword` varchar(300) COLLATE utf8mb4_unicode_520_ci NOT NULL, `priority` int unsigned NOT NULL, `created_at` datetime NOT NULL, `updated_at` datetime NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `key_data_type_id_keyword` (`data_type`, `data_id`, `keyword`), INDEX `index_data_type` (`data_type`), INDEX `index_data_id` (`data_id`), INDEX `index_keyword` (`keyword`), INDEX `index_priority` (`priority`), INDEX `index_key_data_type_id_keyword_priority` (`data_type`, `data_id`, `keyword`, `priority`), INDEX `index_created_at` (`created_at`), INDEX `index_updated_at` (`updated_at`) ) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_520_ci;
Tuy nhiên mình muốn các bạn tập trung sự chú ý nhiều hơn vào bảng
ezy_data_indices, ý nghĩa của các trường trong bảng này là:- id: Là trường dữ liệu được tăng dần.
- data_type: Là kiểu của dữ liệu, thông thường bạn sẽ dùng tên bảng cần được đánh chỉ cho trường này, ví dụ bạn muốn đánh chỉ mục cho dữ liệu của bảng
ecommerce_products(lưu thông tin của sản phẩm) thì data type sẽ bằngecommerce_products. - data_id: Là id của bản ghi, ví dụ bạn có một sản phẩm có id là 3 thì data_id sẽ bằng 3.
- keyword: Là từ khoá gắn với data_id, bạn sẽ cần tách một dữ liệu dài ra thành các từ khoá nhỏ hơn để lưu vào bảng
ezy_data_indices. - priority: Là độ ưu tiên của từ khoá, ví dụ bạn có thể lưu
Red carcóprioritylà7cònRedlà3để khi truy vấn thì có sắp xếp theo priority, kết quả có độ khớp cao hơn sẽ được xếp lên đầu.
Thiết kế lớp
Từ bảng
ezy_data_indices EzyPlatform sẽ sinh ra các lớp sau để hỗ trợ các nhà phát triển không cần phải khởi tạo lại nữa: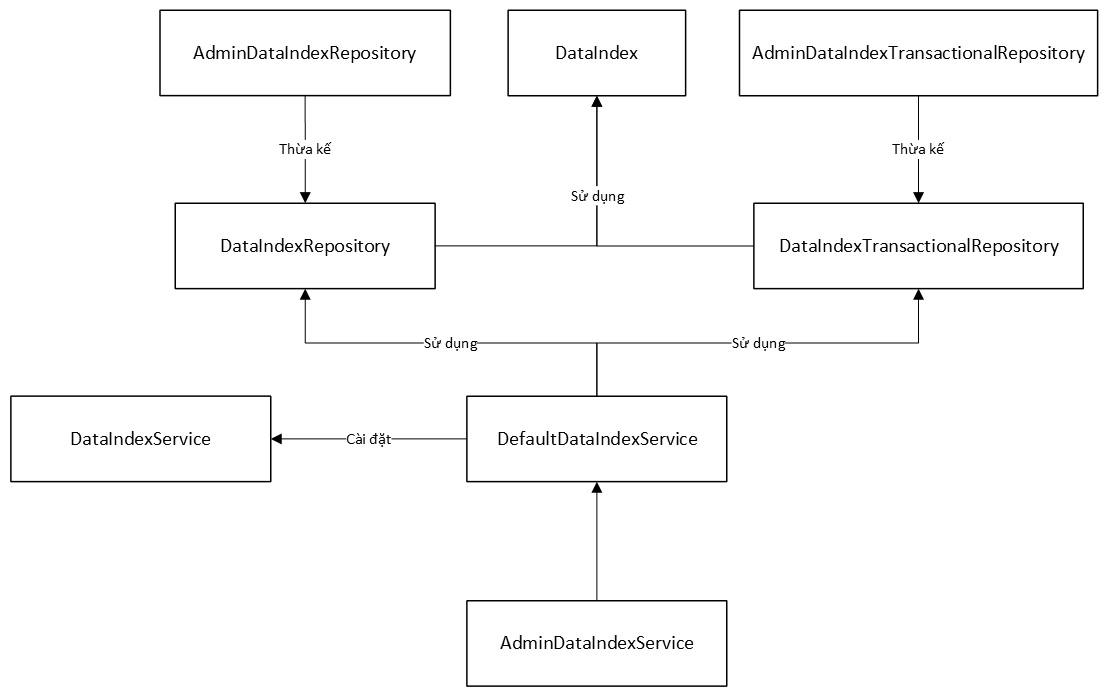
- DataIndex: Đây là lớp Entity ánh xạ với bảng
ezy_data_indices. - DataIndexRepository: Interface này cung cấp một số hàm cơ bản CRUD cho DataIndex.
- Lớp DataIndexTransactionalRepository: Cung cấp hàm lưu DataIndex, vì sẽ có nhiều luồng ghi các chỉ mục vào bảng
ezy_data_indicesnên cần sử dụng transaction để đảm bảo tính ACID. - DataIndexService: Interface này cung cấp các hàm cơ bản CRUD cho các chỉ mục.
- DefaultDataIndexService: Lớp này cài đặt interface DataIndexService và sử dụng cả DataIndexRepository lẫn DataIndexTransactionalRepository để cài đặt các hàm cần thiết.
- AdminDataIndexService: Đây là lớp mà bạn sẽ hay sử dụng nhất để lưu chỉ mục vào bảng
ezy_data_indices.
Các bước lưu dữ liệu chỉ mục vào cơ sở dữ liệu
Các bước này bao gồm:
- Tách dữ liệu lớn thành các từ khoá ngắn.
- Set độ ưu tiên cho từ khoá.
- Lưu các chỉ mục vào cơ sở dữ liệu.
Ví dụ bạn cần lưu dữ liệu chỉ mục của các sản phẩm vào cơ sở dữ liệu bạn có thể làm như sau:
List<String> keywords = new ArrayList<>(); String productCode = value.getProductCode(); if (isNotBlank(productCode)) { keywords.addAll(toKeywords(productCode)); } String productName = value.getProductName(); if (isNotBlank(productName)) { keywords.addAll(toKeywords(productName)); } long productId = value.getId(); List<ProductCategory> categories = productCategoryRepository .findByProductId(productId); for (ProductCategory category : categories) { keywords.addAll(toKeywords(category.getDisplayName())); } List<ProductTag> tags = productTagRepository .findByProductId(productId); for (ProductTag tag : tags) { keywords.addAll(toKeywords(tag.getName())); } logger.info( "extracted keyword of productId {}: {}", productId, keywords ); List<String> distinctKeywords = keywords .stream() .distinct() .collect(Collectors.toList()); List<SaveDataKeywordModel> dataRecords = distinctKeywords.stream() .map(keyword -> SaveDataKeywordModel.builder() .dataId(productId) .keyword(keyword) .priority(keyword.length()) .build() ) .collect(Collectors.toList()); this.dataIndexService.saveKeywords("ecommerce_products", dataRecords);
Ở đây bạn đang lấy tất cả các thông tin từ mã sản phẩm, tên danh mục, tag cho đến tên sản phẩm thông qua hàm
Keywords.toKeywords do EzyPlatform cung cấp để tách thành các từ khoá nhỏ, độ ưu tiên được set theo độ dài của từ khoá và sau đó lưu tất cả vào cơ sở dữ liệu.Cách hàm toKeywords tách từ
Hàm này cung cấp thuật toán để tách các từ lớn thành các từ nhỏ có độ dài tối đa, mặc định tối đa là 300 ký tự ví dụ bạn có từ
Lucky Wheel Game nó sẽ tách thành các từ có độ dài khác nhau như:"lucky wheel game", "lucky wheel", "lucky", "wheel", "game", "luc", "whe", "gam", "lu", "wh", "ga"
Hay
a/b/c sẽ được tách thành:"a b c", "a b", "a", "b", "c"
Tổng kết
Vì không thể lạm dụng công nghệ một cách tràn lan nên EzyPlatform không thể đưa các framework đánh chỉ mục dữ liệu như Elasticsearch vào phần core được nên việc sử dụng bảng
ezy_data_indices là một giải pháp nhẹ nhàng và phù hợp. Nếu dữ liệu của bạn hoặc khách hàng bạn có thể lớn đến hàng chục hay trăm nghìn bản ghi, hãy cân nhắc sử dụng các bảng và các lớp EzyPlatform cung cấp để đánh chỉ mục dữ liệu nhé.